
How we build with AI
No hype-driven AI usage here; we start with real problems and use AI when it’s the right tool for the job. Read more below.
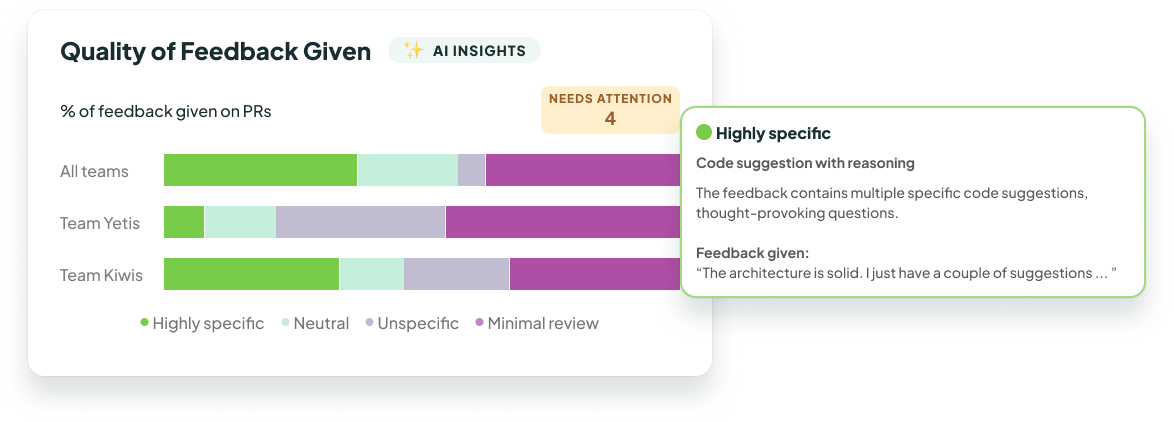
Our Approach to AI
Our approach to AI is a natural extension of our data principles. We understand that models are probabilistic, non-deterministic, and their outputs can vary.
Start with a real problem
We don't build AI because it's trendy. We build it when there's a genuine use case that matters to our users. For example, our first AI feature, Feedback Quality, came after years of engineering teams telling us that feedback quantity metrics alone weren’t enough. Traditional NLP couldn't provide a requisite level of accuracy, but LLMs could. AI has real environmental impacts, so we only use it when it delivers a genuine step change in value for our customers.
Rigorous and participatory evaluation
Every AI feature we ship is grounded in robust evals. We work with academics and domain experts to create ground-truth datasets and use-case specific accuracy measures. We test with a diverse range of users, including underrepresented groups, to catch bias early and design for fairness.
For more about how we design and use evals, read this evals post.
Transparency makes AI better
Our belief is that transparency drives better outcomes. From day one, users can see how our classifications work, disagree with labels, and flag errors. This openness builds trust and accountability — and ensures AI keeps improving through human feedback. We’re proud to maintain some of the most transparent documentation of any engineering analytics tool and share publicly about how we build AI features.
AI works best alongside humans
We design AI systems to support people, not substitute them. That means creating feedback loops from the start, explaining decisions clearly, and giving users full control, including the ability to switch AI features off whenever they want. AI works best when it works with humans as an enabler.
Building AI
AI systems are inherently biased. From data collection, model design to the way we measure accuracy, Multitudes takes mitigation steps to build ethically and responsibly.
Research informed development
Our team works with academic researchers and domain experts throughout our development process. This means reading ML papers, nerding out on math, debating statistical approaches and having our methodologies challenged. But we balance rigor with pragmatism. Our goal is always to serve our users' needs, not to pursue perfection for its own sake.
Data collection and labelling
When we build ground truth datasets, we ensure we use sampling techniques help build a dataset that is representative of the population. Secondly, we ensure we label the data using domain experts and a diverse range of people to reduce bias (see more why here). Before finalising any ground-truth dataset, we measure and monitor inter-rater reliability statistics like Cohen's Kappa (κ).
LLM design
Our modeling approach is grounded in academic research and industry best practices. We employ techniques like task modularization and symbol tuning to improve performance. We use tools like BAML that help us optimize for user experience rather than wrestling with LLM inconsistencies. When we discovered women were six times more likely to flag feedback as negative, we refined our prompts and approach rather than accepting the result. This kind of prompt refinement in response to discovered biases is a core part of how we iterate.
Accuracy metrics
We go beyond standard evaluation measures such as accuracy, precision, recall and f-scores. Each feature delivers a unique user experience, so our model and prompt selection reflects those specific requirements. Learn about some unique metrics we used for our Feedback Themes feature here.
Our AI features

Feedback Quality
Learn how we use AI and machine learning to surface insights about the quality of feedback in your team's code reviews.
Read the docs
→
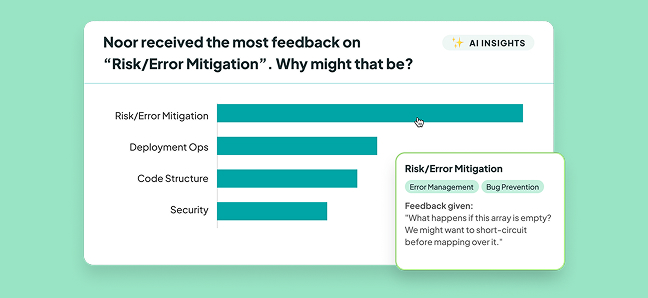
Feedback Themes
Learn how we use AI and machine learning to surface insights about the quality of feedback in your team's code reviews.
Read the docs
→
What’s the ROI of your AI tooling?
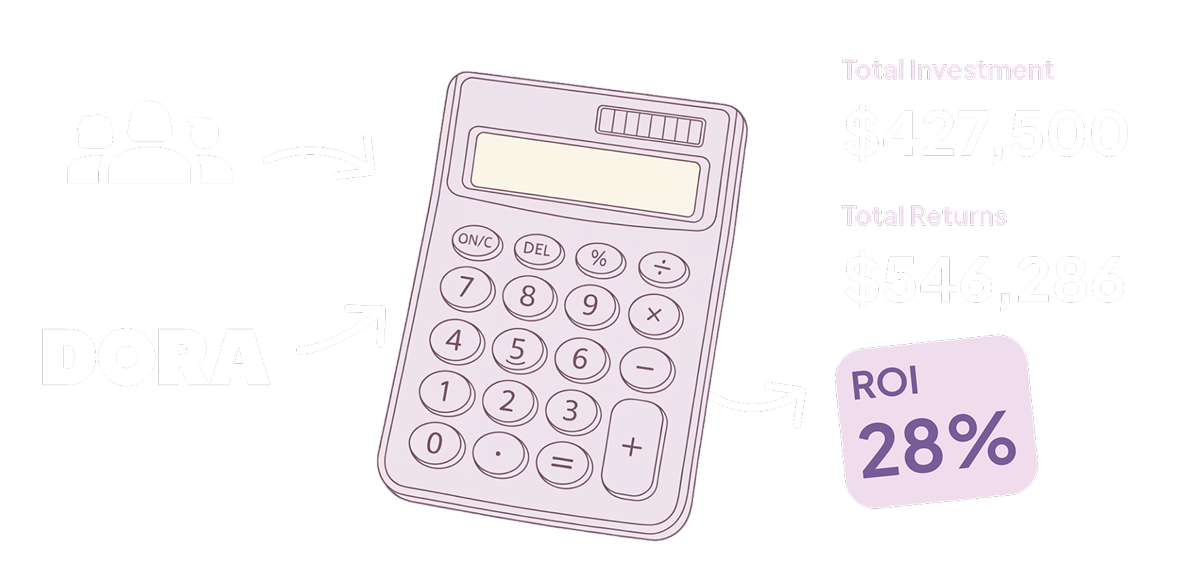
Start making data-informed decisions.
Get useful insights on team performance and culture, along with updates on our product!
© Copyright 2026 Multitudes Limited. All rights reserved.

.svg)
.svg)
.svg)